Part 06
Planning in Agents + Reasoning Models
Woah! We’re more than halfway through our course!
Over the past few parts, we talked about what agents can do:
Use tools
Retrieve information through RAG
Pass everything in a clean format using MCP
But all of that assumes something fundamental:
That the agent actually knows what to do next.
And that’s where things often break.
Today, we shift focus from tools and inputs to how agents think — more specifically, how modern models are starting to plan and why that changes how we design real-world systems.
Why Planning Matters in Agentic Systems
Here are a few examples to start with.
If you ask an agent:
“What’s 13 multiplied by 47?”
…it can either solve it directly or call a calculator. This is a one-step task — no real planning needed.
Now imagine asking:
“Find all our Q1 clients in the healthcare sector, check which ones are overdue on payments, and draft personalized emails with new payment links.”
In this case, the agent needs to:
Understand the instruction
Break it into manageable parts
Retrieve the right data
Choose tools
Perform steps in order
Handle exceptions
Know when the task is done
That loop of interpreting, sequencing, and acting is planning.
The agent (meaning the model) is expected to figure this out on its own — including which tools to use and how to apply the information it has.
Why Traditional LLMs Struggle With Planning
Most general-purpose LLMs were never trained to do this.
They are trained to predict the next token based on the previous context — nothing more.
They excel at:
Continuing sentences
Generating summaries
Answering direct questions
…but they behave more like short-sighted generators.
They complete what’s in front of them but aren’t wired to think ahead.
When asked to act as agents in multi-step, decision-making tasks, they tend to:
Skip steps
Repeat actions
Overcomplicate simple things
Lose the plot halfway through
Early Attempts to Improve Reasoning
To patch this gap, builders experimented with prompting techniques to nudge planning behavior.
A popular example: Chain-of-Thought prompting — adding “Let’s think step by step” to break tasks into stages.
This worked for logic puzzles and structured Q&A, but fell short for real agents working with:
Tools
Unpredictable inputs
Changing state
Because underneath, these models still weren’t trained for planning — they were just responding to prompt tricks.
Then Came Reasoning Models
The next shift: train models to plan by design.
This gave rise to Large Reasoning Models (LRMs).
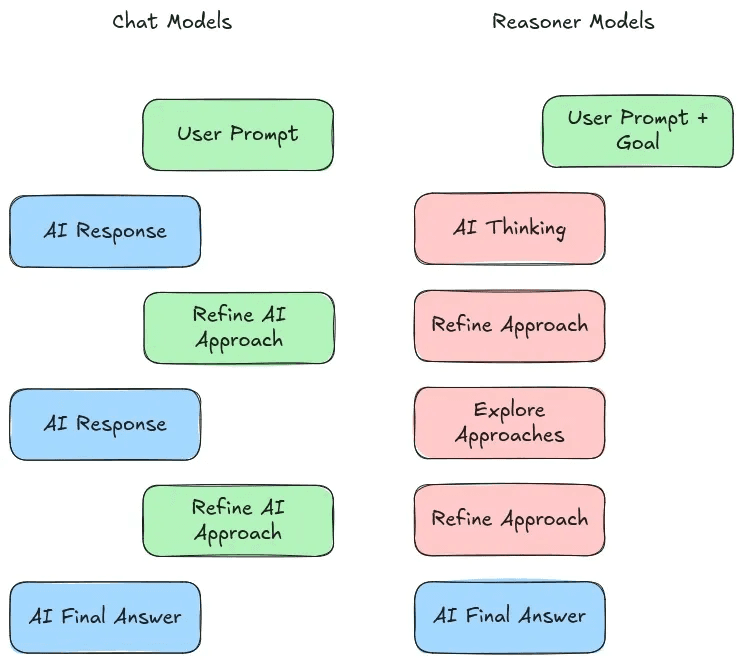
LLMs:
input → LLM → output statement
LRMs:
input → LRM → plan step + output statement
All still text, but LRMs are nudged during training to think before acting.
Examples:
OpenAI’s o-series (o1, o3) — first public examples
DeepSeek’s DeepSeek-R1 — tuned for tool-augmented reasoning and planning
Google’s Gemini thinking models
Anthropic’s Claude 3.7 reasoning mode
Some even activate reasoning only when needed.
How They Fit in Agentic Design
The main value of reasoning models is in improving the planning component — the part that asks:
“What should I do next, and why?”
In enterprise use cases, planning is where agents often fail.
Reasoning models can help, but they aren’t magic.
Use Them With Caution
Reasoning models are still new and come with tradeoffs:
Overthink simple tasks
Generate longer outputs
Increase latency and cost
Can hallucinate logical-sounding but incorrect plans
Rule of thumb:
Don’t start with a reasoning model.
Begin with a mid-size base model.
Only switch if you see clear planning failures — and even then, evaluate the real impact.
Up Next
In the next part, we’ll shift to another core component of agents: memory — how agents can remember effectively and why it matters.
Created by