Part 10
AI Agent Lessons and What's Ahead
A Quick Recap
Here’s what we covered over the last 9 parts:
Part 1 — What agents are: Not just chatbots that generate text, but systems that can decide and act.
Part 2 — Types of agents: From tightly controlled workflow agents to fully autonomous ones, depending on how much decision-making you hand over.
Part 3–4 — Tools and RAG: The bread and butter of agent action and knowledge grounding.
Part 5 — MCP: A clean way to structure everything an agent needs (tools, memory, prior messages) into one payload.
Part 6 — Planning and reasoning models: Why plain LLMs aren’t enough for complex decisions, and how newer models are built for multi-step tasks.
Part 7 — Memory: Short-term vs. long-term memory, what to store, how to retrieve, and why it matters for continuity.
Part 8 — Multi-agent systems: Orchestration, peer-to-peer collaboration, and the messiness of coordination.
Part 9 — Real-world systems: How Perplexity, NotebookLM, and DeepResearch likely use these patterns in different ways.
We’ve covered the moving parts that show up in real-world systems.
But all of it falls apart if you’re not thinking about two things: observability and evaluation.
What’s Still Hard
Observability
Observability means tracking what your agent is doing — at every step. You’ll want:
Logs of tool calls, decisions, retries
Metrics to spot bottlenecks in latency and cost
Visibility into when things go off-rail
Step-wise traceability for debugging
Tools like Comet Opik help with this.
Design observability from day one, especially for high-autonomy agents.
Evaluation
Agents are non-deterministic.
You need continuous evaluation, not just manual testing.
At a minimum, track:
Goal or task completion rates
Tool call success/failure
RAG quality and hallucination metrics
Model overthinking or inefficiency
Latency and token usage at each step
Evaluation is how you understand and improve your system.
Too many teams do vibe checks instead of real evals — and get stuck in PoC purgatory.
Think of evals + observability as your testing pipeline — the agentic equivalent of software QA.
Metrics will vary by use case, but the discipline is the same.
Where Things Are Headed in Agentic AI
This space is early, but here are clear trends:
1. Protocols > Prompts
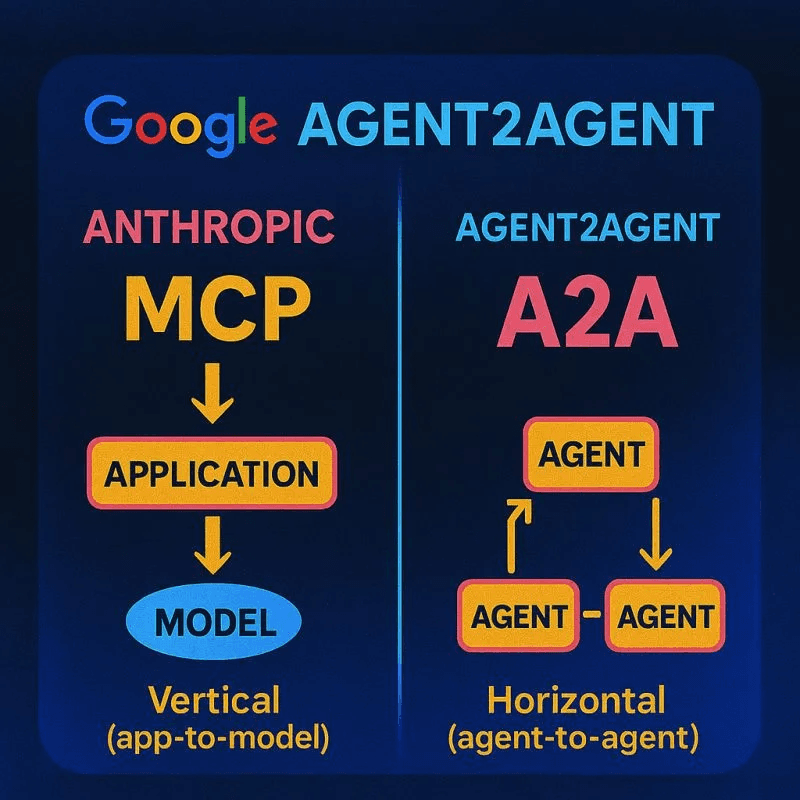
Image Source: Reuven’s LinkedIn post
As systems grow, we’ll move away from handcrafted prompts toward shared standards.
MCP (Model Context Protocol) standardizes how we package structured context — tools, memory, RAG, prior instructions.
A2A (Agent-to-Agent), released by Google, focuses on cross-platform agent communication with a shared schema.
Expect cleaner abstractions over time — though it’ll take a while before anything becomes as standard as HTTP.
2. Hybrid Reasoning Models
Reasoning models will evolve toward selective planning — knowing when to plan vs. act fast.
We’re already seeing this with Claude 3.7 and others.
The aim: balance intelligence with efficiency — without overthinking every task.
3. Better Memory Systems
Today’s memory is mostly duct-taped in.
The future: memory that knows what to recall, when, and why.
Expect:
Task-scoped memory
Session-based memory
Persona-specific memory
And easier management.
4. Tool Ecosystem Maturity
Right now, everyone’s building custom tools/wrappers. Over time:
Trusted, plug-and-play APIs
Better abstraction layers
Shared security practices
Just like microservices matured in traditional software, tools will mature in the agentic stack.
A Final Word
If you’ve followed along, you’ve seen the theme:
We didn’t start with architecture.
We started with problems.
That’s the real mindset shift:
Don’t chase agents for the hype.
Build them when they make solving a problem easier, faster, or smarter.
Start simple. Measure everything. Scale when needed.
Agent-first thinking breaks. Problem-first thinking scales.
Thanks for reading, sharing, and thinking along during these 10 parts.
If you take away one thing from this series — let it be this:
Problem first, always.
Check out the readme for more lectures and advanced topics. If this was helpful, feel free to forward it to someone looking to learn in this space. And if you’d like to go deeper, our full 6-week course covers system design, applied agentic concepts, and real evaluation workflows, the kind that support production-grade applications. The course is built for everyone, whether you’re a Product Manager, Architect, Director, C-suite leader, or someone seriously exploring agentic AI.
Our next cohort starts soon. Our next cohort starts soon. Early bird pricing is live: use the code "GITHUB" to get $300 off (Valid only for August 2025) to register here!!
Created by